QueryGPT: Cách Uber Biến Câu Hỏi Tiếng Anh Thành SQL Bằng Generative AI
Tìm hiểu cách Uber xây dựng QueryGPT — hệ thống dùng LLM, vector database và RAG để tự động tạo câu truy vấn SQL phức tạp từ ngôn ngữ tự nhiên, giúp giảm thời gian soạn query từ 10 phút xuống còn 3 phút.
Mục lục
SQL là ngôn ngữ hàng ngày của hàng nghìn kỹ sư, quản lý vận hành và nhà khoa học dữ liệu tại Uber. Nhưng không phải ai cũng rành SQL. Và ngay cả người rành, việc soạn một câu query phức tạp trên schema hàng trăm cột vẫn mất nhiều thời gian.
QueryGPT ra đời để giải quyết bài toán đó: nhập câu hỏi bằng tiếng Anh bình thường, nhận lại câu SQL hoàn chỉnh.
1. Động lực: Tại sao phải làm QueryGPT?
Mỗi tháng, nền tảng dữ liệu của Uber xử lý khoảng 1.2 triệu truy vấn tương tác. Trong đó, nhóm Vận hành (Operations) đóng góp khoảng 36% — một con số khổng lồ, phần lớn đến từ những người không phải kỹ sư chuyên nghiệp.

Trung bình, một người cần 10 phút để soạn một câu query. Với QueryGPT, thời gian đó rút xuống còn 3 phút — tiết kiệm 70% thời gian mỗi lần.

Kết quả hiện tại sau khi ra mắt hạn chế với nhóm Operations và Support: khoảng 300 người dùng hoạt động mỗi ngày, với 78% báo cáo rằng họ soạn query nhanh hơn trước.
2. Phiên bản đầu tiên: Hackdayz v1
Hệ thống khởi đầu từ một cuộc hackathon nội bộ. Ý tưởng đơn giản: dùng RAG (Retrieval-Augmented Generation) kết hợp với tìm kiếm K-Nearest Neighbor để lấy ngữ cảnh phù hợp trước khi gọi LLM.

Cụ thể, quy trình như sau:
- Người dùng nhập câu hỏi bằng tiếng Anh.
- Hệ thống vector hóa câu hỏi, tìm 3 bảng liên quan và 7 câu SQL mẫu gần nhất.
- Tất cả ngữ cảnh được đưa vào prompt của LLM để sinh ra câu SQL.
Phiên bản này hoạt động được với 7 bảng tier-1 và 20 câu SQL mẫu. Nhưng khi mở rộng, các vấn đề nghiêm trọng xuất hiện.
Ví dụ: Schema bảng uber.trips_data

Hệ thống còn cần xử lý các quy ước đặc thù của Uber như cách tính ngày tháng trong nội bộ:

Và đây là ví dụ câu SQL được sinh ra từ phiên bản đầu tiên:

Ba vấn đề cốt lõi của v1
1. Semantic matching yếu: So sánh độ tương đồng thuần túy trên câu lệnh CREATE TABLE và SELECT không phản ánh được ý nghĩa nghiệp vụ. Người dùng hỏi về “chuyến xe bị hủy” nhưng hệ thống lại kéo về bảng không liên quan.
2. Không hiểu ý định: Chuyển từ câu hỏi tự nhiên sang schema phù hợp cần một bước phân loại trung gian. Không có bước này, kết quả thiếu chính xác.
3. Token explosion: Các bảng tier-1 của Uber có đến 200+ cột. Một schema đầy đủ tiêu tốn 40.000–60.000 token, vượt giới hạn của nhiều model và đội chi phí API lên rất cao.
3. Kiến trúc hiện tại: Hệ thống Multi-Agent
Uber thiết kế lại QueryGPT từ nền tảng, đưa vào ba tầng agent chuyên biệt.
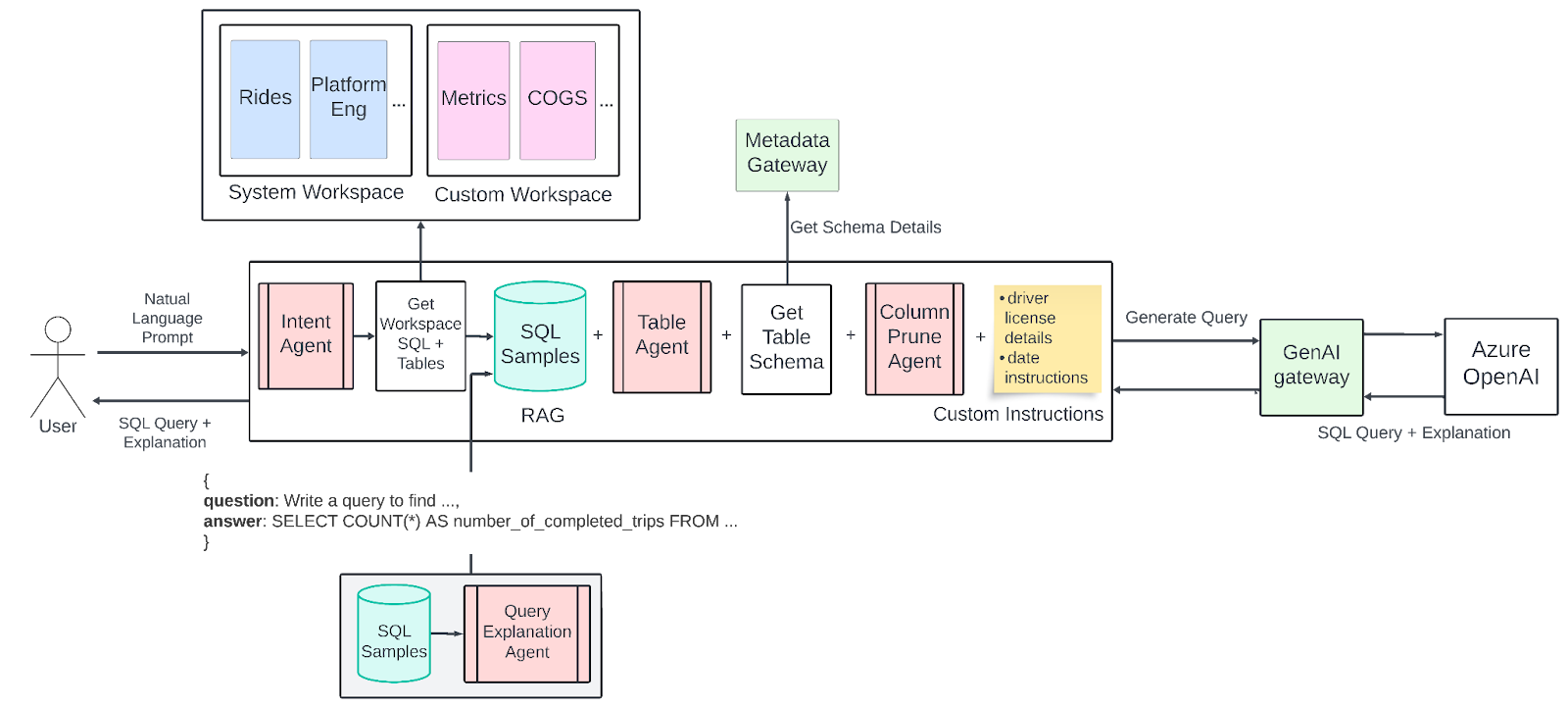
Workspaces — Tổ chức dữ liệu theo nghiệp vụ
Thay vì để toàn bộ hàng nghìn bảng vào một “mớ hỗn độn”, QueryGPT tổ chức chúng thành các workspace theo từng domain nghiệp vụ:
| Workspace | Nội dung |
|---|---|
| Mobility | Chuyến xe, tài xế, tài liệu |
| Ads | Quảng cáo, chiến dịch |
| Core Services | Dịch vụ lõi |
| Platform Engineering | Hạ tầng kỹ thuật |
| IT | Nội bộ |
Ngoài ra, người dùng có thể tự tạo workspace riêng cho nhu cầu đặc thù.
Intent Agent — Hiểu câu hỏi trước khi tìm kiếm
Đây là điểm khác biệt lớn so với v1. Thay vì tìm kiếm ngay, Intent Agent dùng LLM để phân loại câu hỏi vào đúng workspace trước. Điều này thu hẹp phạm vi tìm kiếm, giảm nhiễu và tăng chính xác đáng kể.
Table Agent — Xác nhận bảng trước khi query

Table Agent đề xuất danh sách bảng liên quan và cho người dùng quyền override — chọn lại bảng khác nếu gợi ý chưa đúng. Đây là cơ chế “human-in-the-loop” quan trọng, giúp hệ thống học từ phản hồi người dùng.
Column Prune Agent — Cắt bớt để tiết kiệm token
Ngay cả với model 128K token context, các bảng lớn vẫn gây vấn đề về chi phí và độ trễ. Column Prune Agent giải quyết bằng cách:
- Nhận schema đầy đủ của bảng.
- Dùng LLM đánh giá từng cột: cột nào liên quan đến câu hỏi, cột nào không.
- Loại bỏ cột không liên quan trước khi đưa vào prompt chính.

Kết quả: giảm đáng kể chi phí API và độ trễ mà không mất thông tin quan trọng.
4. Framework Đánh Giá
Làm sao biết QueryGPT có thực sự hoạt động tốt không? Uber xây dựng một hệ thống đánh giá nghiêm ngặt.
Bộ câu hỏi chuẩn (Evaluation Set)
Nhóm kỹ sư thu thập câu hỏi thực tế từ log của QueryGPT, sau đó xác minh thủ công:
- Intent đúng không?
- Schema cần thiết là gì?
- Câu SQL “vàng” (golden SQL) là gì?
Bộ câu hỏi này bao gồm nhiều domain nghiệp vụ khác nhau để đảm bảo độ đa dạng.
Hai luồng đánh giá
Vanilla Flow: Chạy toàn bộ pipeline từ đầu đến cuối — từ nhận câu hỏi, phân loại intent, chọn bảng đến sinh SQL. Đo hiệu năng thực tế.
Decoupled Flow: Bỏ qua các bước đầu, cung cấp trực tiếp intent và danh sách bảng đúng. Đo chất lượng của riêng bước sinh SQL, tách biệt khỏi các bước trước.
Các chỉ số đo lường
| Chỉ số | Ý nghĩa |
|---|---|
| Intent Accuracy | Intent được phân loại có đúng không |
| Table Overlap Score | Mức độ trùng khớp giữa bảng được chọn và bảng cần thiết (0–1) |
| Successful Execution | Query có chạy không lỗi không |
| Output Validation | Query có trả về ít nhất 1 dòng dữ liệu không |
| Query Similarity | Độ tương đồng với golden SQL do LLM đánh giá (0–1) |




Giới hạn của framework đánh giá
Không có hệ thống đánh giá nào hoàn hảo. Với QueryGPT, ba giới hạn chính là:
- LLM không deterministic: Cùng một câu hỏi, kết quả có thể khác nhau ~5% giữa các lần chạy.
- Không thể bao phủ toàn bộ: Uber có hàng trăm nghìn dataset — bộ test chỉ là mẫu nhỏ.
- Nhiều cách đúng: Một câu hỏi có thể có nhiều câu SQL đúng khác nhau, không phải chỉ một “golden SQL”.
5. Bài học từ thực tế
LLM rất giỏi phân loại — nếu được giao đúng việc
Intent Agent, Table Agent, Column Prune Agent đều hoạt động hiệu quả vì chúng được thiết kế để làm một việc cụ thể, rõ ràng. Khi giao cho LLM nhiệm vụ quá rộng (“làm tất cả mọi thứ”), hiệu quả giảm rõ rệt. Khi tách nhỏ thành các agent chuyên biệt, mỗi agent làm tốt phần việc của mình.
Đây là bài học áp dụng được cho bất kỳ hệ thống AI nào: decompose thành các task nhỏ, rõ ràng thay vì để một model xử lý tất cả.
Hallucination vẫn là thách thức chưa giải quyết triệt để
Các câu SQL được sinh ra đôi khi tham chiếu đến bảng hoặc cột không tồn tại. Uber đang giải quyết bằng prompt engineering, cho phép người dùng chat nhiều vòng để tinh chỉnh, và đang nghiên cứu validation agent tự động kiểm tra SQL trước khi trả về.
Câu hỏi của người dùng thường thiếu ngữ cảnh
Có người nhập câu hỏi rất chi tiết với đầy đủ thuật ngữ. Có người chỉ nhập 5 từ và có lỗi chính tả. Uber giải quyết bằng Prompt Expander — một bước tiền xử lý dùng LLM để mở rộng câu hỏi ngắn thành câu hỏi có đủ ngữ cảnh trước khi đưa vào pipeline chính.
Thanh chất lượng cho SQL cao hơn nhiều so với text thông thường
Người dùng kỳ vọng SQL được sinh ra chạy được ngay lập tức. Một câu trả lời “gần đúng” trong chat thì được chấp nhận, nhưng một câu SQL có lỗi cú pháp thì không. Điều này đặt ra yêu cầu cao hơn nhiều về độ chính xác so với các ứng dụng AI thông thường.
Kết luận
QueryGPT là ví dụ điển hình cho việc ứng dụng AI tạo sinh vào bài toán thực tế với quy mô lớn. Ba điểm đáng học nhất từ dự án này:
- Kiến trúc multi-agent chuyên biệt hiệu quả hơn nhiều so với một model “làm tất cả”.
- Human-in-the-loop (Table Agent với override) là cơ chế thiết yếu để hệ thống AI hoạt động tin cậy ở production.
- Evaluation framework nghiêm ngặt là điều kiện bắt buộc để cải tiến liên tục — không đo được thì không cải thiện được.
Với 300 người dùng hoạt động mỗi ngày và 78% báo cáo tiết kiệm thời gian, QueryGPT đang mở ra quyền truy cập dữ liệu cho những người trước đây phải phụ thuộc vào kỹ sư mỗi khi cần một con số.
Tham khảo: Uber Engineering Blog — QueryGPT: Natural Language to SQL Using Generative AI
Tác giả gốc: Jeffrey Johnson, Callie Busch, Abhi Khune, Pradeep Chakka và đội ngũ Data Platform tại Uber.